人工智能在影视文娱,以及游戏等行业具备广泛的应用场景,核心主线就在于内容生产力的释放与升级方面。一方面,整体提升文娱产业工 业化水平,形成AI赋能全流...
2024-03-07 11 人工智能AI行业报告
云端训练:云端即数据中心,对神经网络而言,训练过程就是通过不断更新网络参数,使推断(或者 预测)误差最小化的过程。云端训练对芯片性能的要求很高,主要包括:(1)计算精度,必须支持具有较 长字长的浮点数或定点数;(2)不仅要具有强大的单芯片计算能力,还要具备很好的扩展性,可以通过多 芯片系统提供更强大的计算能力;(3)对内存数量、访问内存的带宽和内存管理方法的要求都非常高; 云端推断:推断过程是指直接将数据输入神经网络并评估结果的正向计算过程。相比训练芯片,推断 芯片考虑的因素更加综合:单位功耗算力,时延,成本等等。终端推断:对于终端推断任务,由于应用场景多种多样,芯片部署在各种设备中,如自动驾驶汽车、 智慧家居产品和各类 IoT 设备等,其需求和约束也呈现出多样化的特点。对于多数应用来说,速度、面积、 能效、安全和硬件成本是最重要的考虑因素,而模型的准确度和数据精度则可以依据、具体情况适当降低。 总的来说,云侧 AI 处理主要强调精度、处理能力、内存容量和带宽,同时追求低延时和低功耗;边 缘设备中的 AI 处理则主要关注功耗、响应时间、体积、成本和隐私安全等问题。
AI 芯片百花齐放,目前主要有三种技术路线 深度学习算法在 2010 年前后兴起,并逐步掀起本轮人工智能浪潮。为了满足深度学习算法对高算力 的要求,学界和业界针对神经网络的特点对原有的芯片架构进行优化,或提出新的芯片架构,目前主要有 GPU、FPGA 和 ASIC 三种技术路线。 GPU 最早被用于加速深度学习算法,是目前应用最成熟的 AI 芯片。GPU 是显卡的核心,最早仅用于 图形渲染,但 GPU 计算能力强大,逐渐被用于通用计算(即通用 GPU)。由于 GPU 发展早,应用普遍, 软件生态成熟完善,尤其是其具备良好的矩阵计算能力和并行计算优势,在执行深度学习算法时相比 CPU 有巨大优势,因此深度学习兴起时,最早被用于 AI 计算,随后在数据中心获得大量应用。但 GPU 不是专 门为了执行 AI 算法而设计的,相比 AI 专用处理器,在执行深度学习算法时存在能耗较高、效率较低等特 点,但英伟达也在持续挖掘其执行深度学习算法的能力。 在云端,通用 GPU,特别是英伟达系列 GPU 芯片,被广泛应用于深度神经网络训练和推理。与 CPU 相比,拥有数千个计算内核的 GPU 可以实现 10-100 倍的吞吐量。英伟达最新的 Tesla V100 除了 GPU 核之 外,还专门针对深度学习设计了张量核(Tensor Cores),能够提供 120 TFLOPS(每秒 120 万亿次浮点指令) 的处理能力。同时,英伟达 GPU 还有比较完善的软件开发环境,是目前 AI 训练领域使用最广泛的平台。
FPGA 具备可编程性,可支持产品快速上市,同时相比 CPU 具备更强的计算能力。FPGA 即现场可编 程门阵列,其利用门电路直接运算,速度快,而用户可以自由定义这些门电路和存储器之间的布线,改变 执行方案。也就是说,FPGA 芯片上的电路可以反复更改,具有很高的灵活性。因此,FPGA 在传统上主 要应用于处理器芯片研发过程中的验证阶段,用于在流片前检验处理器设计的正确性。近年来,因为 FPGA 灵活性较好、处理简单指令重复计算比较强,用在云计算架构形成 CPU+FPGA 的混合异构中相比 GPU 具 备更低功效和高性能,适用于高密度计算,在深度学习的推理阶段有着更高的效率和更低的成本,使得全 球科技巨头纷纷布局云端 FPGA 生态。
")
标签: 电子行业报告 人工智能AI行业报告
相关文章

人工智能在影视文娱,以及游戏等行业具备广泛的应用场景,核心主线就在于内容生产力的释放与升级方面。一方面,整体提升文娱产业工 业化水平,形成AI赋能全流...
2024-03-07 11 人工智能AI行业报告

中国移动自主构建语言、视觉、语音等多种类型大模型,具备跨行业供给侧增强、高可控性、异构软硬件灵活部 署几大显著的技术特色,整体性能指标实现国内主流水平...
2024-03-06 9 人工智能AI行业报告

大模型的兴起,打开了产业通向数据驱动、智能决策 时代的大门。此前IBM商业价值研究院曾在其《值得押 注的七大投资决策》报告中指出,未来十年,生成式 A...
2024-03-06 12 人工智能AI行业报告
这些发现表明 , 发达经济体可能更容易受到人工智能采用带来的劳动力市场变化的影响 , 这种变化在比新兴市场经济体和低收入国 家更短的时间内实现。鉴于发...
2024-03-06 9 人工智能AI行业报告
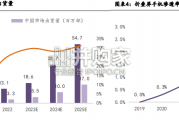
2023年全球手机市场持续低迷,折叠屏手机异军突起, 是目前手机市场里唯一保持上升趋势的细分市场。据 Counterpoint全球折叠屏手机出货量将从...
2024-03-05 22 电子行业报告

硬件端:Vision Pro顶级配置实现性能突破。2016虚拟现实元年以来,硬件端持续迭代,2023年Meta发布其首款消费级MR一体机, 2024年...
2024-03-05 40 电子行业报告
最新留言