OpenClaw 核心能力的不断成熟与全面开放,引发了业界的关注热潮。得益 于其底层架构的灵活性与高扩展性,OpenClaw 不仅支撑了大量基于它的二...
2026-05-21 7 人工智能AI行业报告
VLA 模型具备成为具身智能基础模型潜力。视觉-语言-动作模型(VLA)代表一类 旨在处理多模态输入与输出的模型,通用性是 VLA 模型的核心特点之一,体现在其 以多模态大语言模型为底座,具备“理解万物”的能力,VLA 模型的理解能力和多 任务泛化能力让模型在不同的应用场景中具备出色表现,展现出超越自动驾驶乃至 机器人等单独垂域应用的潜力,有望成为广义具身智能基础模型范式。 VLA 模型是自动驾驶向知识驱动、体验优先升级的技术基础。我们认为汽车领域智 能化的最终形式是实现驾驶领域的通用人工智能,而非简单的汽车电子软件智能化, 这使得汽车从第三人称智能化向第一人称智能化、由数据驱动向知识驱动进化成为 自动驾驶进化的未来趋势,而 VLA 模型特别是其中语言类大模型的成功引入则奠定 了范式转变的技术基础。底层技术逻辑升维也带动了车端应用焦点由基本功能实现 向人车交互性、极端场景通过性等体验提升转变,中期维度看,不同车企自动驾驶 的模型性能领先、功能领先将转化为体验领先并重塑汽车行业产品生态,知识驱动 范式的智能化模型也将重新定义自动驾驶,行业将真正开启电动智能化下半场角逐。
")
标签: 人工智能AI行业报告
相关文章

OpenClaw 核心能力的不断成熟与全面开放,引发了业界的关注热潮。得益 于其底层架构的灵活性与高扩展性,OpenClaw 不仅支撑了大量基于它的二...
2026-05-21 7 人工智能AI行业报告

2025年全球 AI产业规模 1.8 万亿美元,其中 AI模型规模 144亿美元,占比 1%: 根据 Gartner 在 2026 年 1 月的数据显...
2026-05-20 22 人工智能AI行业报告

使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 41 人工智能AI行业报告
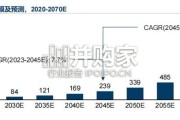
目前中国市场仍处于初期发展阶段,但表现出显著的增长潜力。截至2023年,中国AI4S市场规模已达到47亿元人民 币,涵盖药物研发、合成生物学、基因测序...
2026-05-18 40 人工智能AI行业报告

需求+政策推动,Token数量指数级增长,产业链协同发展大受益:从海外的ChatGPT、Sora到国内的文心一言、Kimi,AI应用正从文本生成向多模...
2026-05-18 49 人工智能AI行业报告
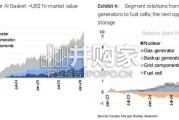
[Download]资源名称:摩根斯坦利报告:人工智能的力量:灵活算力——AI增长的下一个浪潮(英文,60页)...
2026-05-11 41 人工智能AI行业报告
最新留言