AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 13 人工智能AI行业报告
国内外差距依然明显。GP T 4 - T u r b o总分 89.79分遥遥领先。高于国内所有大模型及 国外代表性大模型。其中国内最好模型文 心一言4.0总分74.02分,距离GPT4-Turbo 有15.77分。 必须看到的是,过去1年国内大模型已经有 了长足的进步。综合能力超过GPT3.5的模 型有8个,分别为百度的文心一言4 . 0、零 一 万 物 的 Y i - 3 4 B - C h a t 、 月 之 暗 面 的 Moonshot、vivo的BlueLM、腾讯的混元、 阿 里 云 的 通 义 千 问 2 . 0 、 清 华 & 智 谱 A I 的 ChatGLM3、字节跳动的云雀。 另外国内开源模型在中文上表现要好于国 外 开 源 模 型 , 如百川智能的 B a i c h u a n 2 - 1 3 B - C h a t、元象科技的XVERS E - 1 3 B - Chat-2、阿里云的Qwen-14、ChatGLM3- 6B的成绩均大幅优于Llama2-13B-Chat。通过SuperCLUE测评结果发现,国内大模型的第一梯队有了更多新的模型加入。如零 一万物的Yi-34B-Chat、腾讯的混元、阿里云的通义千问2.0。你方唱罢我登场,已有 模型的新版本或出现的新模型,可能会进一步加剧第一梯队大模型的竞争。 在新的大模型竞争中,创业公司和大厂都有一定的优势。大厂有多年积累和大量用户的 优势,可以大量获得用户数据和反馈。但一线创业公司同样存在快速技术迭代的优势。多轮开放式问题基准SuperCLUE-OPEN,是使用超级模型作为评判官, 用一个待评估模型与一个基准模型(GPT3.5)进行对比,从而得出胜平负的 得分。 从胜率来看,全球领跑者GPT4-Turbo胜率为49.34%,和率为48.19%, 大幅领先于其他模型,而败率仅为2 . 4%,足以说明GPT 4 - T u rbo对 GPT3.5在各项能力上的全面压倒性优势。 而国内模型中,零一万物的Yi-34B-Chat和百度的文心一言4.0不相上 下,胜率的趋势基本相同,并且表现均好于GPT4。胜率超过20%的还 有Moonshot、BlueLM、ChatGLM3-Turbo、腾讯混元、通义千问2.0 和云雀大模型。 在200亿参数量级的开源模型中Baichuan2-13B-Chat的胜率排在首位, 展 现 出 不 俗 的 对 战 能 力 。 排 在 2 至 3 位 的 是 Q w e n - 1 4 B - C h a t 和 XVERSE-13B-Chat-2,同样表现可圈可点。
")
标签: 人工智能AI行业报告
相关文章

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 13 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 21 人工智能AI行业报告
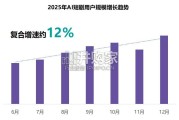
AI漫剧市场规模发展迅速。依托庞大的AI短剧用户群体及持续增长的用户趋势,仅2025年,其在抖音端的累计播放量 就达到了757.7亿。进入下半年,AI...
2026-04-30 37 人工智能AI行业报告

随着大模型“智能涌现”效应的持续深化,AI产业的叙事逻辑正从单纯的语义对话(Chatbot 转向具备闭环执行能力的智能体(Agent 形态。在刚过去的...
2026-04-30 49 人工智能AI行业报告

本报告由知乎研究院与中国信息通信研究院人工智能研究所联合发 布,旨在为 AI 时代的品牌营销提供一套科学的度量衡,推出「品牌 AI 竞争力...
2026-04-30 36 人工智能AI行业报告
最新留言