预计 24 年电视全球零售额稳健增长,北美、西欧增速较快。据欧睿数据,预计 24 年电视全球零售额为 1180 亿美元,同比+0.6%,其中亚太/西欧...
2025-04-17 15 电子行业报告
由于H200本身算力部分并没有变化,因此换用H200并不会对AI大模型的训练速度产生更好的影响,以训练175B大小的GPT-3举例,同规模的 H200大概只比H100快10%左右。 H200主要的提升之处在于"推理”:推理对于算力的需求并不高,限制反而在于单芯片的显存大小以及显存带宽,如果应用到多GPU的互联, 那么信息通信的带宽反而会不够。即便如NV Link提供的900GB/s的数据通信速度,也无法媲美单卡内部超过3TB/s的速度,更不用说换了 HBM3e显存后高达4.8TB/s的性能。更大的单卡显存容量也能有效减少跨卡访问的次数,算是一种变相的效率提升。 买的越多,省得越多。随着当前AI大语言模型逐步迈向应用化,计算任务的重心已经由早期的训练模型转变为应用端的推理行为。而H200对 比H100的推理能耗直接减半,极大降低了使用成本。英伟达是设计公司,并不直接生产芯片,它需要请台积电生产芯片,从其他公司采 购高性能内存,再交给供应商组装成一张卡。一颗 H100 的成本约 3000 美元,而英 伟达卖 30000 多美元,翻十倍。 H200的141GB内存,与H100的80GB相比直接提升76%。作为首款搭载HBM3e内 存的GPU,内存带宽也从3.35TB/s提升至4.8TB/s,提升43%。在HBM3e加持下, H200让Llama-70B推理性能几乎翻倍,运行GPT3-175B也能提高60%。 英伟达向台积电下订单,用 4 纳米的芯片产线制造 GPU 芯片,平均每颗成本 155 美元。
")
标签: 电子行业报告
相关文章

预计 24 年电视全球零售额稳健增长,北美、西欧增速较快。据欧睿数据,预计 24 年电视全球零售额为 1180 亿美元,同比+0.6%,其中亚太/西欧...
2025-04-17 15 电子行业报告
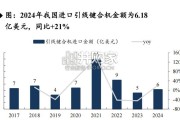
受下游需求影响及我国设备商国产替代加速,2024年我国引线键合机进口市场空间约6.18亿美元,仍显著低于 2021年高峰期进口市场空间的15.9亿美元...
2025-04-11 42 电子行业报告
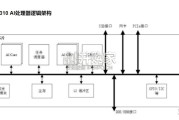
满足飞速发展的深度神经网络对芯片算力的需求,昇腾AI处理器本质上是一个SoC(System on Chip)。以昇腾310 AI 处理器为例,主要可以...
2025-03-29 75 电子行业报告


最新留言