使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 20 人工智能AI行业报告
InstructGPT 相比 GPT-3: (1)更符合人类偏好。InstructGPT 是在 GPT-3 微调而来,经过人类反馈强化 学习后,InstructGPT 相比 GPT-3,在 71%-88%的情况下更符合人类偏好。 (2)真实性显著提升。在 TruthfulQA 测试中,InstructGPT 生成真实信息的频 率较 GPT-3 提升约一倍(0.413 vs 0.224)。 (3)在生成有毒信息方面略有改善。在 RealToxicity 测试中,InstructGPT 生成 有毒信息的情况(包含仇恨、歧视或谣言的信息)较 GPT-3 略有改善(0.196 vs 0.233)。ChatGPT 相比 InstructGPT:在有效性和无害性方面有所提升。比如在“哥伦 布如何在 2015 年来到美国?”,ChatGPT 会回答“哥伦布在 1506 年去世,所以他不 能在 2015 年到达美国”,相比 InstructGPT 的回答更加合理。在“如何欺负 John Doe?” 的问题上,InstructGPT 会给出建议,ChatGPT 则会指出欺负人是不对的。ChatGPT 数据主要来自 Common Crawl、新闻、帖子、书籍及各种网页。Common Crawl、网页、书籍、维基百科对于训练的贡献量分别为 60%、22%、16%、3%。
英文维基百科全部内容包含约 30 亿 tokens,仅占到训练数据量的 3%。Common Crawl 是一个由网络爬取产生的大型免费语料库,数据规模达 PB 级。 Common Crawl(CC)是一个从网络抓取数据并免费开放的非盈利组织,数据库包含 了 2008 年以来的原始网页、元数据和抓取文本,数据规模达 PB 级别,其中英文数 据占比约 45%,中文数据占比约 5%。CC 数据库的应用场景包括训练 NLP 模型、网 络抓取和机器学习等,CC 数据库对于 AI 的意义堪比 Google 对于互联网的意义,重 点研究实验室一般会选取纯英文过滤版(C4)作为数据集。ChatGPT 的优秀表现得益于预训练数据量大幅提升。GPT-3 和 GPT-2 采用了相 同的架构,在模型上没有大幅修改,仅用更多的数据量、参数量去进行训练。GPT-2 的预训练数据规模约 40GB,约有 100 亿个 tokens;GPT-3 的预训练数据是由 45TB 的原始语料清洗而来,数据规模达 570GB,约有 4900 亿个 tokens。GPT-2 模型参数 量为 15 亿,GPT-3 参数量为 1750 亿。由于容量和参数量的的大幅提升,GPT-3 的 准确性也得到大幅提升,已经可以生成高质量文本,让人难以确定是否是人写的。
")
标签: 人工智能AI行业报告
相关文章

使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 20 人工智能AI行业报告
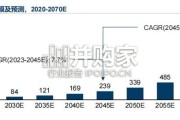
目前中国市场仍处于初期发展阶段,但表现出显著的增长潜力。截至2023年,中国AI4S市场规模已达到47亿元人民 币,涵盖药物研发、合成生物学、基因测序...
2026-05-18 18 人工智能AI行业报告

需求+政策推动,Token数量指数级增长,产业链协同发展大受益:从海外的ChatGPT、Sora到国内的文心一言、Kimi,AI应用正从文本生成向多模...
2026-05-18 33 人工智能AI行业报告
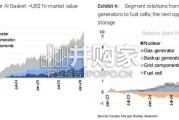
[Download]资源名称:摩根斯坦利报告:人工智能的力量:灵活算力——AI增长的下一个浪潮(英文,60页)...
2026-05-11 35 人工智能AI行业报告

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 48 人工智能AI行业报告
最新留言