[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 28 人工智能AI行业报告
百度文心一言NLP方向算法储备齐全: 其中著名的 ERNIE系列,是基于知识增强的千亿模型,用于智能创作、摘要生成、问答、语义检 索、情感分析、信息抽取、文本匹配、文本纠错等各类自然语言理解和生成任务,并且模型已经可应用于医疗、金融、图语言、编程、 跨模态、信息抽取等各个方面。此外,PLATO模型,是全球首个超百亿参数规模的中英文对话训练模型,可以让机器人像人一样具有逻 辑且自由对话。 百度文心一言NLP功能强大: 例如ERNIE系列,ERNIE3.0基于知识增强的多范式统一预训练框架,深入融合的千亿级知识,具备强大的语 言理解能力与小说、摘要、文案创意、歌词、诗歌等文学创作能力。其中与鹏城实验室合作发布了知识增强千亿大模型 “鹏城-百 度·文心“。目前文心ERNIE已经刷新93个中文NLP任务基准,并多次登顶SuperGLUE全球榜,已在机器阅读理解、文本分类、语义相似 度计算等60多项任务中实际应用。
百度文心一言CV具有颠覆性: VIMER-CAE: 为视觉自监督预训练大模型,创新性地提出 “在隐含的编码表征空间完成掩码预测任务”的 预训练框架,在图像分类、目标检测、语义分割等经典下游任务上刷新SOTA结果。 VIMER-UFO 2.0: 多任务学习模型,行业最大170亿参数视觉多任务模型,覆盖人脸、人体、车辆、商品、食物细粒度分类等 20+ CV 基 础任,具备支持各类任务、各类硬件的灵活部署等优势,可以有效解决大模型参数量大,推理性能差等问题。 OCR -VIMER-StrucTexT 2.0: 为表征学习预训练模型解决了训练数据匮乏和传统 OCR + NLP 链路过长导致的模型表达能力不足、优化 效率偏低等问题,能够广泛应用于文档、卡证、票据等图像文字识别和结构化理解,例如泛卡证票据信息抽取应用、政务办公文档还原 应用等场景。 VIMER-UMS: 是行业首个统一视觉单模态与多源图文模态表征的商品多模态预训练模型,可实现统一图文表征预训练同时覆盖商品视觉 单模态、多模态识别与检索任务,可以显著改善商品视觉检索和商品多模态检索体验。
")
标签: 人工智能AI行业报告
相关文章

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 28 人工智能AI行业报告
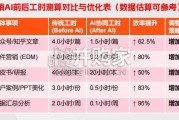
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 34 人工智能AI行业报告

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 37 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 31 人工智能AI行业报告
最新留言