[Download]资源名称:摩根斯坦利报告:人工智能的力量:灵活算力——AI增长的下一个浪潮(英文,60页)...
2026-05-11 10 人工智能AI行业报告
模型能力不仅与模型大小有关,还与数据 大小和总计算量有关。同时,预训练数据 的质量对取得良好的性能起着关键作用, 因此在扩展预训练语料库时,数据收集和 清洗策略是非常重要的考虑。 预训练语料库的来源大致可以分为两类: 通用数据:如网页、书籍和对话文本, 由于其庞大、多样化和可访问性,被 大多数LLM使用,可以增强LLM的语 言建模和泛化能力。 专业数据:如多语言数据、科学数据 和代码,使LLM具有特定的任务解决 能力。并行训练。由于模型规模巨大,成功训练一个强大的LLM是非常具有挑战性的。 LLM的网络参数学习通常需要联合使用多种并行策略, 一些优化框架已经发布,以促进并行算法的实现和部署,如Transformer、DeepSpeed和Megatron-LM。
此外,优化技巧对训练稳定 性和模型性能也很重要。 最近,GPT-4提出开发特殊的基础设施和优化方法,用小得多的模型的达到大型模型的性能。 目前,常用的训练LLM的库包括Transformers,DeepSpeed、Megatron-LM、JAX、Colossal-AI、BMTrain、FastMoe等。此外, 现有的深度学习框架(如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore和OneFlow)也提供了对并行算法的支持。Transformer由Google 在2017年的论文 Attention is All you need 中提出,GPT与BERT均采用了Transformer模型。 Transformer基于显著性的注意力机制为输入序列中的任何位置提供上下文信息,使得Transformer具有全局表征能力强, 高度并行性,位置关联操作不受限,通用性强,可扩展性强等优势,从而使得GPT模型具有优异的表现。
")
标签: 人工智能AI行业报告
相关文章
[Download]资源名称:摩根斯坦利报告:人工智能的力量:灵活算力——AI增长的下一个浪潮(英文,60页)...
2026-05-11 10 人工智能AI行业报告

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 35 人工智能AI行业报告
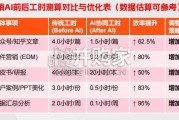
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 42 人工智能AI行业报告

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 43 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 33 人工智能AI行业报告
最新留言