[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 19 人工智能AI行业报告
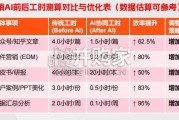
不同模型得分及精度转换:根据Tim Dettmers等人的论文,团队使用大模型GPT-4当裁判,对不同模型的回答进行打分,以 GPT-3.5的成绩作为100%,最终GPT-4自己的得分是114.5%。Michal Kosinski的研究表明,GPT-3可以解决70%的心智理论任 务,而GPT-3.5解决了93%的任务,以GPT-3.5的成绩作为100,GPT-3的分数约为75(70/93*100)。如果使用分数对精度进行 衡量,则GPT-4精度相当于GPT-3.5的1.145倍,GPT-3精度相当于GPT-3.5的0.75倍。 此外,如果New Bing目前使用的模型为压缩约6倍后的模型,所需算力约减少到原来的六分之一。同样,模型的质量会受到 一定的影响,压缩后大约从GPT-3.5下降到GPT-3的水平,具体其打分换算过来约76.2分。
在2500万DAU的假设条件下,若每个用户10次的使用次数,GPT-3.5所需GPU数量大约为27.2万A100。如果2024年Bing Chat 的DAU达2500万,每个用户提10次问题,若按照芯片75%的使用效率进行测算,GPT-3.5所需GPU数量大约为27.2万 (2500*10turns/1224 turns/0.75 GPU utilization rate)。若根据精度下降10%,算力除以2的逻辑,可以推算出GPT-4 在2500万日活及10次平均使用次数下条件下所需算力大约为66.4万(27.2 GPU/(2^log0.9(114.5/100))。 在同样的假设条件下,若New Bing之后使用压缩6倍的模型(得分76.2分),所需算力约为4.5万GPU。如果微软对模型进 行压缩,压缩后的模型使用4块芯片,其算力需求约为4.5万。同样地,在相同假设前提下,GPT-3所需的算力约为4.1万 (27.2 GPU/(2^log0.9(75/100) 。根据机器之心,GPT-4的推理成本是Davinci模型(GPT-3.5为Davinci3)的3倍,与我们 测算结果相似。
")
标签: 人工智能AI行业报告
相关文章

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 19 人工智能AI行业报告
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 21 人工智能AI行业报告

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 30 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 27 人工智能AI行业报告
最新留言