[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 31 人工智能AI行业报告
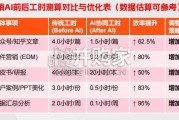
大模型的训练效果、成本和时间与算力资源有密切 的关系。大模型发展浪潮有望进一步增加 AI 行业对智 算算力的需求规模。 1.1.1 国外大模型的发展 大模型数量加速增长,算力成为模型竞赛底座。自 2018 年以来,海外云厂商巨头接连发布 NLP 大模型。 据赛迪顾问 2023 年 7 月发布的数据显示,海外大模型 发布数量逐年上升,年发布数量在五年中由 2 个增长至 48 个。且仅 2023 年 1-7 月就发布了 31 个大模型。 自 2021 年起,海外大模型数量呈现加速增长的趋 势,结合 2023 年 1-7 月的情况,该趋势有望延续。2018 年 6 月, OpenAI 发布了 Transformer 模型 ——GPT-1,训练参数量 1.2 亿。同年 10 月,谷歌发布 了大规模预训练语言模型 BERT,参数量超过 3 亿。 2019 年,OpenAI 推出 15 亿参数的 GPT-2。2019 年 9 月,英伟达推出了 83 亿参数的 Megatron-LM。同 年,谷歌推出了 110 亿参数的 T5,微软推出了 170 亿 参数的图灵 Turing-NLG。 2020 年,OpenAI 推出了大语言训练模型 GPT-3, 参数达到 1750 亿。微软和英伟达在同年 10 月联合发 布了 5300 亿参数的 Megatron-Turing 大模型。 2021 年 1 月,谷歌推出 Switch Transformer 模型, 参数量达到 1.6 万亿,大模型参数量首次突破万亿。 2022 年,OpenAI 推出基于 GPT-3.5 大模型的 ChatGPT,宣告了 GPT-3.5 版本的存在。 2023 年,OpenAI 推出 GPT-4,估计参数规模达到 1.8 万亿。GPU 数量与不同量级大模型所需的算力之间的线 性关系。根据 2021 年 8 月 Deepak Narayanan 等人发布 的论文,随着模型参数增加,大模型训练需要的总浮点 数与 GPU 数量呈现正相关的线性关系。175B 参数量级 的大模型所需的 A100 级别芯片数量为 1024 片(Token 数为 300B,训练 34 天情况下)。当参数增长到 1T 时, 大模型训练所需的 A100 芯片数量为 3072 片(Token 数 为 450B,训练 84 天情况下)。
")
标签: 人工智能AI行业报告
相关文章

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 31 人工智能AI行业报告
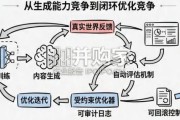
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 35 人工智能AI行业报告

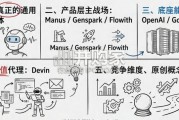
AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 39 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 31 人工智能AI行业报告
最新留言