AI 发展带动训练集群规模扩大,推理端 token 消耗算力持续增长,带动算力和网络需求。我们认为,CPO 可以有效帮 助大规模集群降低功耗、提升互联...
2026-05-08 49 电子行业报告
由于H200本身算力部分并没有变化,因此换用H200并不会对AI大模型的训练速度产生更好的影响,以训练175B大小的GPT-3举例,同规模的 H200大概只比H100快10%左右。 H200主要的提升之处在于"推理”:推理对于算力的需求并不高,限制反而在于单芯片的显存大小以及显存带宽,如果应用到多GPU的互联, 那么信息通信的带宽反而会不够。即便如NV Link提供的900GB/s的数据通信速度,也无法媲美单卡内部超过3TB/s的速度,更不用说换了 HBM3e显存后高达4.8TB/s的性能。更大的单卡显存容量也能有效减少跨卡访问的次数,算是一种变相的效率提升。 买的越多,省得越多。随着当前AI大语言模型逐步迈向应用化,计算任务的重心已经由早期的训练模型转变为应用端的推理行为。而H200对 比H100的推理能耗直接减半,极大降低了使用成本。英伟达是设计公司,并不直接生产芯片,它需要请台积电生产芯片,从其他公司采 购高性能内存,再交给供应商组装成一张卡。一颗 H100 的成本约 3000 美元,而英 伟达卖 30000 多美元,翻十倍。 H200的141GB内存,与H100的80GB相比直接提升76%。作为首款搭载HBM3e内 存的GPU,内存带宽也从3.35TB/s提升至4.8TB/s,提升43%。在HBM3e加持下, H200让Llama-70B推理性能几乎翻倍,运行GPT3-175B也能提高60%。 英伟达向台积电下订单,用 4 纳米的芯片产线制造 GPU 芯片,平均每颗成本 155 美元。
")
标签: 电子行业报告
相关文章

AI 发展带动训练集群规模扩大,推理端 token 消耗算力持续增长,带动算力和网络需求。我们认为,CPO 可以有效帮 助大规模集群降低功耗、提升互联...
2026-05-08 49 电子行业报告

ASIC 设计服务行业技术壁垒与规模效应构筑护城河,服务商价值在先 进制程下加速重估。1)技术端:先进制程复杂度确立服务商核心枢纽 地位。随着摩尔定律...
2026-05-06 22 电子行业报告
MLCC下游应用领域广泛,国产替代空间巨大。MLCC具有温度范围宽、电 容范围宽、介质损耗小、体积小、价格低等特点,广泛应用于移动终端、 高端装备、汽...
2026-05-05 26 电子行业报告

日系黑电:依靠垂直生产优势+彩色 CRT 技术革新登顶全球,平板时代战略失误逐步边缘化。1950s-1965 年起步期, 在通产省政策扶持下,企业从美...
2026-05-05 27 电子行业报告
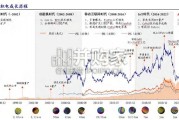
晶圆代工赛道兼具高资本与生态壁垒,台积电的成功印证了生态-技术-产能-订单 的飞轮法则,本土 Fab 已经在生态、技术及产能有所铺垫,当前赢来多重催化...
2026-05-03 47 电子行业报告

AIoT 视觉消费市场,作为物联网产业中靠近 C 端、场景化特点显著的核心赛道,在政策调整、 供应链变革、技术迭代与消费需求升级的多重作用下,2025...
2026-04-28 37 电子行业报告
最新留言