使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 30 人工智能AI行业报告
Sora横空出世引领多模态产业革命。美国时间2月15日,文生视频大模型Sora横空出世,能够根据文本指令或静态图像生成1分钟的 视频。其中,视频生成包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,同时也接受现有视频扩展或填补缺失的帧。总体 而言,不管是在视频的保真度、长度、稳定性、一致性、分辨率、文字理解等方面,Sora都做到了业内领先水平,引领多模态产业革 命。此外,当 Sora 训练的数据量足够大时,它也展现出了一种类似于涌现的能力,从而使得视频生成模型具备了类似于物理世界通 用模拟器的潜力。 拆解视频生成过程,技术博采众长或奠定了Sora文生视频领军地位。从技术报告中,Sora视频生成过程大致由“视频编码+加噪降噪 +视频解码”三个步骤组成,视频压缩网络、时空patches、transformer架构、视频数据集等技术与资源在其中发挥了重要作用。 视频压缩网络:过往VAE应用于视频领域通常需插入时间层,Sora从头训练了能直接压缩视频的自编码器,可同时实现时间和空间的 压缩,既节省算力资源,又最大程度上保留视频原始信息,或为Sora生成长视频的关键因素,并为后续处理奠定基础。 时空patches:1)同时考虑视频中时间和空间关系,能够捕捉到视频中细微的动作和变化,在保证视频内容连贯性和长度的同时,创 造出丰富多样的视觉效果;2)突破视频分辨率、长宽比等限制的同时显著提升模型性能,节约训练与推理算力成本。 Transformer架构:1)相比于U-Net架构,transformer突显Scaling Law下的“暴力美学”,即参数规模越大、训练时长越长、训 练数据集越大,生成视频的效果更好;2)此外,在transformer大规模训练下,逐步显现出规模效应,迸发了模型的涌现能力。 视频数据集:Sora或采用了更丰富的视频数据集,在原生视频的基础上,将DALL・E3的re-captioning技术应用于视频领域,同时利 用GPT保障文字-视频数据集质量,使得模型具有强大的语言理解能力。
")
标签: 人工智能AI行业报告
相关文章

使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 30 人工智能AI行业报告
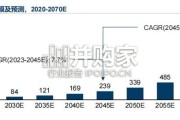
目前中国市场仍处于初期发展阶段,但表现出显著的增长潜力。截至2023年,中国AI4S市场规模已达到47亿元人民 币,涵盖药物研发、合成生物学、基因测序...
2026-05-18 26 人工智能AI行业报告

需求+政策推动,Token数量指数级增长,产业链协同发展大受益:从海外的ChatGPT、Sora到国内的文心一言、Kimi,AI应用正从文本生成向多模...
2026-05-18 38 人工智能AI行业报告
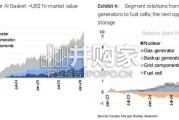
[Download]资源名称:摩根斯坦利报告:人工智能的力量:灵活算力——AI增长的下一个浪潮(英文,60页)...
2026-05-11 38 人工智能AI行业报告

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 48 人工智能AI行业报告
最新留言