龙虾作为一款Skill免费、月费token几十块的工具,能让使用者上头到什么程度?他们已经不只是「用一用」,而是开始为它改装自己的工作环境。近四分之一...
2026-05-21 26 人工智能AI行业报告
DeepSeek大幅降低了应用成本。DeepSeek-V3的训练成本仅为2.788M H800 GPU小时,同时其支持FP8混合精度训练,并针对训练框架进行了全面优化, 以实现加速训练和降低GPU内存使用,通过算法、框架和硬件的共同设计,克服了跨节点MoE训练中的通信瓶颈,显著提高了训练效率并降低了训练成本 。 DeepSeek每百万输入tokens成本为0.55美元,每百万输出tokens成本为2.19美元,相较于ChatGPT O1模型,输入和输出成本均降低了96%。 DeepSeek通过创新算法使推理效率大幅优化。DeepSeek-V3采用了多头潜在注意力(Multi-head Latent Attention,MLA)和DeepSeekMoE架构,显著提 高了推理速度和显存利用率,能够在保持模型性能的同时实现高效的训练和推理。MLA架构能够大幅提升模型推理效率。MLA(Multi-head Latent Attention)跨层注意力特征融合架构架构是DeepSeek模型中的一种注意力机制优化技 术,通过低秩联合压缩注意力键(Key)和值(Value),显著降低了推理过程中的KV缓存,同时保持了与标准多头注意力(MHA)相当的性能。MLA架构 在保持模型性能的同时,通过压缩技术减少了内存占用和计算量,从而提高了模型的推理效率。 MoE稀疏化能够控制激活参数数量,提升模型计算效率。MoE(Mixture of Experts)通过将模型划分为多个“专家”模块,每个专家专注于处理特定的 任务或数据子集。在训练和推理过程中,只有部分专家被激活,从而减少了不必要的计算。MoE架构能够显著降低计算开销,提高模型的训练和推理效 率。此外,MoE架构还具有高度的可扩展性,通过增加专家的数量,可以进一步提升模型的性能,而不会显著增加计算成本。
")
标签: 人工智能AI行业报告
相关文章
龙虾作为一款Skill免费、月费token几十块的工具,能让使用者上头到什么程度?他们已经不只是「用一用」,而是开始为它改装自己的工作环境。近四分之一...
2026-05-21 26 人工智能AI行业报告

OpenClaw 核心能力的不断成熟与全面开放,引发了业界的关注热潮。得益 于其底层架构的灵活性与高扩展性,OpenClaw 不仅支撑了大量基于它的二...
2026-05-21 17 人工智能AI行业报告

2025年全球 AI产业规模 1.8 万亿美元,其中 AI模型规模 144亿美元,占比 1%: 根据 Gartner 在 2026 年 1 月的数据显...
2026-05-20 24 人工智能AI行业报告

使用Palantir系统时,操作者可以获得全流程的全局掌控。组织级系统整合了ERP、CRM、PLC、MES等多源独立数据,打破了任一 单独企业软件的能...
2026-05-18 41 人工智能AI行业报告
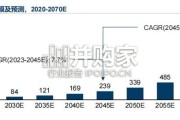
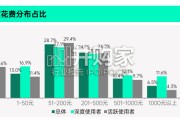
目前中国市场仍处于初期发展阶段,但表现出显著的增长潜力。截至2023年,中国AI4S市场规模已达到47亿元人民 币,涵盖药物研发、合成生物学、基因测序...
2026-05-18 41 人工智能AI行业报告

需求+政策推动,Token数量指数级增长,产业链协同发展大受益:从海外的ChatGPT、Sora到国内的文心一言、Kimi,AI应用正从文本生成向多模...
2026-05-18 50 人工智能AI行业报告
最新留言