人工智能OPC(一人公司)是指在人工智能技术的协同支持下,个人创业者可独立完成从产品设计、技术研发、产品制造到市场投放、用户运营、客户服务等全链路业务...
2026-06-05 42 人工智能AI行业报告
ChatGPT 采用监督学习+奖励模型进行语言模型训练。ChatGPT 使用来自人类反馈的强化 学习 (RLHF) 来训练该模型。首先使用监督微调训练了一个初始模型:人类 AI 训练员提 供对话,他们在对话中扮演双方——用户和 AI 助手。其次,ChatGPT 让标记者可以访问 模型编写的建议,以帮助他们撰写回复。最后,ChatGPT 将这个新的对话数据集与原有数 据集混合,将其转换为对话格式。具体来看,主要包括三个步骤: 1)第一阶段:训练监督策略模型。在 ChatGPT 模型的训练过程中,需要标记者的参与监 督过程。首先,ChatGPT 会从问题数据集中随机抽取若干问题并向模型解释强化学习机制, 其次标记者通过给予特定奖励或惩罚引导 AI 行为,最后通过监督学习将这一条数据用于微 调 GPT3.5 模型。
第二阶段:训练奖励模型。这一阶段的主要目标,在于借助标记者的人工标注,训练出 合意的奖励模型,为监督策略建立评价标准。训练奖励模型的过程同样可以分为三步:1、 抽样出一个问题及其对应的几个模型输出结果;2、标记员将这几个结果按质量排序;3、 将排序后的这套数据结果用于训练奖励模型。 3)第三阶段:采用近端策略优化进行强化学习。近端策略优化(Proximal Policy Optimization) 是一种强化学习算法,核心思路在于将 Policy Gradient 中 On-policy 的训练过程转化为 Off-policy,即将在线学习转化为离线学习。具体来说,也就是先通过监督学习策略生成 PPO 模型,经过奖励机制反馈最优结果后,再将结果用于优化和迭代原有的 PPO 模型参数。往 复多次第二阶段和第三阶段,从而得到参数质量越来越高的 ChatGPT 模型。
")
标签: 人工智能AI行业报告
相关文章
人工智能OPC(一人公司)是指在人工智能技术的协同支持下,个人创业者可独立完成从产品设计、技术研发、产品制造到市场投放、用户运营、客户服务等全链路业务...
2026-06-05 42 人工智能AI行业报告
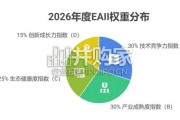
本报告基于自主研发的“中国具身智能产业发展指数(EAII)”评价体系, 对 2025-2026 年度中国具身智能产业发展水平进行系统性评估。评估显示,...
2026-06-03 32 人工智能AI行业报告

综合业界实践与技术白皮书,一个真正的 AI-Native 应用,其设计与构建应系统性地体现 AI First 的核心理念,并在以下六个维度上达到深度融...
2026-06-03 63 人工智能AI行业报告

在美国,AI搜索正从传统搜索的补充演变为用户的默认信息入口,并深度介入从认知、比较到决策的全过程,使品牌是否被AI理解与提及直接影响用户选择。在此基础...
2026-06-01 47 人工智能AI行业报告

OpenClaw(前身为ClawdBot/Moltbot),由奥地利开发者打造,是一个开源的本地优先(Local-First)AI Agent框架。在...
2026-06-01 40 人工智能AI行业报告
最新留言