[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 25 人工智能AI行业报告
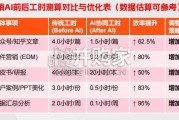
现阶段大模型在处理任务的广泛性上还有很大提升空间,虽然 GPT-4、Gemini 1.5、Claude 3 等模型已经能够处理文本、图像、视频等多模态输入,但尚未具备独立决策和执行行动 的能力。此外,现阶段更多的模型仍聚焦在某单一领域进行性能提升,比如 Kimi 在处理 长文本输入领域表现突出,但尚不能进行图片生成;Sora 能够高质量完成文生视频任务, 但不具备问答功能。因此,现阶段评价大模型性能情况、分析模型演进方向,仍需根据模 型专长领域进行分类。将语言大模型的底层框架和训练方式应用于机器人的感知、决策、控制成为现阶段重 要趋势。2021 年 OpenAI 推出基于 Transformer 架构和对比学习方法的 VLM(视觉 -语言模型)CLIP;2022 年起,谷歌先后推出 RT-1/RT-2/RT-X/RT-H 系列模型,同 样采用 Transformer 架构,能够将语言描述的任务映射为机器人行动策略;24 年 3 月,初创公司 Figure 与 OpenAI 合作推出机器人 Figure01,由 OpenAI 提供视觉推 理和语言理解能力,Figure01 能够描述看到的一切情况、规划未来的行动、语音输 出推理结果等。语言大模型能力相对完备,底层技术路线大多选择 Transformer Decoder-only 架构, 结合MOE和多模态embedding,算法细节优化方向区别较小。以GPT-4、Gemini 1.5、 Claude 3 为例,语言大模型在推理、长文本、代码生成领域已经能够完成初级任务, 但距复杂、专业水平仍有差距; 多模态大模已经能够面向 B\C 端提供商业化产品,底层技术路线主要采用 Diffusion Transformer,但细节优化空间较大,高质量和成规模的数据集仍在发展初期; 具身智能类大模还在探索阶段,底层技术路线尚不清晰,数据收集、训练方法、测评 方法等都处于发展初期。在实际应用场景中准确率较低。
")
标签: 人工智能AI行业报告
相关文章

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 25 人工智能AI行业报告
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 29 人工智能AI行业报告

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 35 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 28 人工智能AI行业报告
最新留言