2023-2025年,海外短剧市场保持高速增长,同时呈现增速分化的态势。用户端,2025年达到21.48亿次,尤其海外用户对短剧的需求持续 释放。收入...
2026-06-04 19 TMT行业报告
2011年,微软研究院提出的基于上下文相关深度神经网络和隐马尔可夫模型的声学模型在大词汇量连续语音识别任务上获 得了显著的性能提升,从此大量研究人员开始转向深度学习在智能语音领域的研究,2016年,机器语音识别准确率第一次 达到人类水平,意味着智能语音技术的落地期到来。近年,研究方向主要是端到端神经网络及针对实际应用中的算法优化。随着智能语音算法基础性能不断提升,识别准确率、时延问题已不再是交互体验的核心痛点,人们希望让智能设备具备更 多的基本能力,例如能够感知环境,当同一个房间里有多个智能交互设备或多台智能交互设备分布在不同的房间时能准确 唤醒,过去通过设备间蓝牙通信可以解决由哪台设备被唤醒与人对话,但无法解决相关的家居控制执行问题。2019年,业 内玩家开始重视将声学感知空间的能力与交互系统结合起来,实现多智能交互设备的就近唤醒应答,避免多设备重复响应 和执行指令,在这种情形下并不存在某个中心交互设备,因此也被称为分布式场景。 未来,设备之间的隔阂可能被进一步打破,如使任何形态、任何配置的终端设备通过连接协议实现AI能力共享、算力共享 (而不仅限于目前用一个设备通过连接协议对其他设备语音控制),就可能使场景内适宜拾音的设备与人交互、适宜功放 的设备配合放音,使多设备的协同达到效率最优。
鉴于目前机器的智能语音交互能力是基于分类任务实现的,其智能程度的提升有赖于技能一项一项地填充补足,最终使交 互体验得到质变。上文介绍了人机对话和语音识别(ASR)的基本实现过程,相比于普通以语音消息作为交互的人机对话, 全双工则是处理语音流,能够实时预测人类即将说出的内容,实时生成回应,并控制对话节奏。多家厂商在持续投入全双 工的研发,全双工、多轮对话、单轮对话对比如下:全双工——只需一次唤醒,保持进行连续的语音流分析(机器保持听 +想的状态,即使在它回话的时候也同步在听和想);多轮对话——只需一次唤醒,听、想、说分离,机器会在它的本句 回话完成后才再次开始听用户说话、听完再分析;单轮对话——每一次用户说话前都需要先唤醒设备。除了基本的对话IQ 与EQ外,让机器实现跨情景流畅切换的全双工(如内容、导航、查询、设备控制的跨情景切换)也是重要研究方向,目 前市场上绝大部分机器都只支持单轮对话或多轮对话,真正搭载了完整、成熟全双工语音能力的产品还很少。
对话引擎是支撑人机交互中问答和对话内容实现的核心,广泛应用于智能客服、智能交互设备、智能车载系统等领域,核 心功能包括语言理解力、对话管理、知识库和帮助开发者定制开发扩展应用的工具。知识的指导对对话引擎十分重要,其 中知识图谱及图谱知识库构建工具能够直接从业务文档抽取知识、建立规则,而不局限于整理好的问答对,这不仅可以帮 助机器找到直接的答案来源,还可以使机器依据元素的属性与关系理解语义、形成话题推荐等对话策略。
")
标签: TMT行业报告
相关文章

2023-2025年,海外短剧市场保持高速增长,同时呈现增速分化的态势。用户端,2025年达到21.48亿次,尤其海外用户对短剧的需求持续 释放。收入...
2026-06-04 19 TMT行业报告

科技发展及现代生活方式深刻地改变着我们 的社交形式,在当下这个转折点上,欧美社 会呈现出极其复杂的新特征: 首先,AI的大范围应用带来的“灵魂震荡”。...
2026-06-04 20 TMT行业报告

在梅特卡夫定律之下,每个交易所都有扩大交易资产品类,建设资金及资产端生态的动力。过往各类交易所泾渭分明 的格局正在被打破,资产类型交易边界逐渐模糊是目...
2026-05-28 28 TMT行业报告
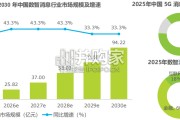
2024—2025年,数智消息处于从传统通道向新赛道发展的规模化验证期,产品市场普及度有限,业务拓展速度较慢,整体市场规 模基数较小。2026—203...
2026-05-21 41 TMT行业报告
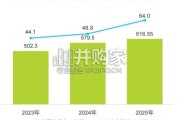
2022年新冠疫情结束后,演出行业迎来井喷式增长,承接2023年的增长,近两年中国演出市场依然呈现强劲复苏后的持续升温态势。无论是票房收入、演出场次还...
2026-05-15 27 TMT行业报告

最新留言