随着大模型与科学智能应用的加速渗透,决定模型能力上限的关 键因素正从更大的参数规模转向更高质量的数据供给:一方面,大模 型的训练、对齐与持续迭代对高质...
2026-05-21 6 云计算行业报告
自然语言处理算法高度依赖于用户的本地数据,例如文本信 息、文档及其标签、问题和选择的答案等,这些数据既可能位于 个人设备上,也可能位于不同机构更大的数据仓库中。在真实的 场景中,用户的自然语言数据是敏感的,可能包含隐私内容,很 难训练出一个健壮的模型来造福用户。将联邦学习应用到自然语 言处理领域中,有助于开发一些隐私保护、个性化的语言模型。 最经典的自然语言处理结合隐私计算的例子是谷歌的利用 移动设备用户数据进行的横向联邦学习,基于移动设备用户频繁 键入的单词来学习词库外(Out-of-Vocabulary,OOV)单词。词 库外单词是指不包含在用户移动设备的词库表中的词汇。词库表 中缺少的单词无法通过键盘提示、自动更正或手势输入来预测。 从单个用户的移动设备学习 OOV 单词来生成模型是不切实际的, 因为每个用户的设备通常只会存储有限大小的词库表。收集所有 用户的数据来训练 OOV 单词生成模型也是不可行的,但 OOV 单词 通常包含用户的敏感内容。因此 2019 年,谷歌实现了首个产品 级的联邦学习系统,主要侧重针对 C 端,在移动手机上运行的联 邦平均算法和分析。联邦学习可以根据所有移动用户的数据,训 练一个共享的 OOV 生成模型,并且不需要将敏感内容传输到中心 服务器或云服务器上。
隐私计算还可以与 NLP 中各种流行的文本分类、序列标记、 对话系统、seq2seq 生成和语言建模等任务结合。例如,目前落 地最多的有:基于 FL 的键盘下一字预测;使用 Text-CNN 的句子 级文本意图分类;使用来自多方的医疗数据对 Bert 进行预训练 和微调,而无需将所有数据聚合到同一位置;将与联邦学习结合 的方法来训练高质量的语言模型,这些模型可以优于在没有联邦 学习的情况下训练的模型;结合联邦学习在医学上完成关系提取 和医学名称实体识别方面等。深度神经网络模型是现代机器视觉的主流技术。支持深度神 经网络模型的一个重要的因素是海量的高质量标注数据。而获得 这些数据往往是成本高昂的。因为对数据的筛选和标注需要大量 的人力和物力成本。在专业性高的领域(比如金融,医疗等领域) 尤其如此。解决高质量标注数据难以获得的一个比较普遍的方案 是数据共享。然而,由于用户隐私、监管风险、缺乏诱因等原因, 许多企业并不愿与其他企业直接共享数据。 联邦学习是替代数据共享,实现知识共享的一种新的学习范 式。在联邦学习中各个参与方(移动设备,企业或机构)的自有 数据不出本地,通过在加密机制下的参数(模型参数或计算中间 结果)交换方式,各个参与方能够在不违反数据隐私的法律法规 情况下,协同地建立一个联邦模型。目前,联邦学习已经在机器 视觉领域中的多个场景落地。
")
标签: 云计算行业报告
相关文章

随着大模型与科学智能应用的加速渗透,决定模型能力上限的关 键因素正从更大的参数规模转向更高质量的数据供给:一方面,大模 型的训练、对齐与持续迭代对高质...
2026-05-21 6 云计算行业报告

2026 年全国AI算力基础设施已从“规模驱动”加速走向“互联互通、监测调度与绿色约束并重”的新阶段;Openclaw 为代 表的新一代智能体加快推广...
2026-05-14 16 云计算行业报告
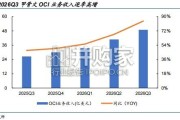
海内外头部算力租赁厂商 ROI 逐步兑现。1)头部算租厂商营收与订单双爆发:海内外算力租赁厂商 ROI 逐步兑 现,甲骨文 FY26Q3 的 OCI...
2026-05-07 41 云计算行业报告

模型跃迁叠加 Agent 出圈引爆推理需求,云厂涨价印证算力斜率依旧。今年以来,我们持 续强调国内算力需求斜率陡峭,核心逻辑在于两大产业趋势共振:1)...
2026-05-02 68 云计算行业报告

2025-2030年,中国数据中心市场新增IT负载预计从5.9GW增至15.1GW,CAGR约+21%,市场规模从2231亿增至6454亿,CAGR约...
2026-04-28 44 云计算行业报告

本报告的核心研究对象是量子计算产业。量子计算机是一种基于量子力学原理构建的计算设备, 是以量子比特(qubit)为基本单元,利用干涉、叠加、纠缠等量子...
2026-04-17 69 云计算行业报告
最新留言