[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 27 人工智能AI行业报告
结合Imagen Video和Phenaki两大模型的优势,推出超长连贯性视频生成模型:Imagen Video是基于级联视频扩散模型的文本条件视频生成系统,即给出文本提示, 就可以通过一个由frozen T5文本编码器、基础视频生成模型、级联时空视频超分辨率模型组成的系统来生成高清视频。Phenaki模型可通过一系列提示在开放域中生 成所有时间段的视频,是谷歌首次以时间变量提示生成视频。 LaMDA Wordcraft:在大语言模型LaMDA基础上开发的、能辅助专业作家写作的AI写文工具,帮助创作者突破“创作瓶颈”。 Audio LM:具备“长期连贯性”的高质量音频生成框架,不需要任何文字或音乐符号表示的情况下,只在极短(三四秒即可)的音频样本基础上训练,可生成自然、 连贯、真实的音频结果,不限语音或者音乐。 文字生成3D模型:通过结合Imagen和最新的神经辐射场 (Neural Radiance Field) 技术,谷歌开发出了DreamFusion技术,可根据现有文字描述,生成具有高保真 外观、深度和法向量的3D模型,支持在不同光照条件下渲染。
将推出Bard对话机器人。2023年2月,谷歌宣布将推出Bard AI聊天机器人,由谷歌大型语言模型LaMDA支持,但参数量更少,使公司能够以更低的成本提供该技术, Bard能在获得简单提示的情况下生成详细答案。2023年2月2日,谷歌研究院等提出了一种视频生成新模型—— Dreamix,受到了AI作图UniTune的启发,将文本条件视频扩散模型 (video diffusion model, VDM)应用于视频编辑。核心是通过两种 主要思路使文本条件VDM保持对输入视频的高保真度:(1)不使用 纯噪声作为模型初始化,而是使用原始视频的降级版本,通过缩小尺 寸和添加噪声仅保留低时空信息;(2)通过微调原始视频上的生成模 型来进一步提升对原始视频保真度。微调确保模型了解原始视频的高 分辨率属性,对输入视频的简单微调会促成相对较低的运动可编辑性, 这是因为模型学会了更倾向于原始运动而不是遵循文本prompt。
")
标签: 人工智能AI行业报告
相关文章

[Download]资源名称:AI原生组织研究报告:OpenClaw推动组织形态重塑(47页)...
2026-05-08 27 人工智能AI行业报告
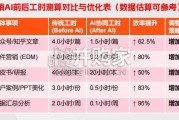
面对 AI 技术的狂飙突进,站在生产力跃升的拐点,我们更愿抛出一个积极的论断:2026 年,大模型不仅不会取代优秀的营销团队, 反而会成为企业构建核心...
2026-05-08 33 人工智能AI行业报告

AI Agent分类体系主要围绕技术实现路径与生态影响模式展开。按技术路径,分为 API Agent与GUI Agent两类。API Agent依托标...
2026-05-07 35 人工智能AI行业报告

“十五五”时期(2026-2030 年)是我国建设社会主义文化强国的关键攻坚期,也是数字文化产业实现高质量发展、 构建全球竞争力的战略窗口期。围绕 国...
2026-05-06 30 人工智能AI行业报告
最新留言