海内外头部算力租赁厂商 ROI 逐步兑现。1)头部算租厂商营收与订单双爆发:海内外算力租赁厂商 ROI 逐步兑 现,甲骨文 FY26Q3 的 OCI...
2026-05-07 29 云计算行业报告
Transformer 的出现开启了大模型演化之路。大语言模型(LLM)是在大量数据集上预训 练的模型,且没有针对特定任务调整数据,其在处理各种 NLP(自然语言处理)任务方面 显示出了较大潜力,如自然语言理解(NLU)、自然语言生成任务等。从 LLM 近年的发展 情况来看,其路线主要分为三种:1)编码器路线;2)编解码器路线;3)解码器路线。从 发展特点来看:1)解码器路线占据主导,归因于 2020 年 GPT-3 模型表现出的优异性能; 2)GPT 系列模型保持领先,或归因于 OpenAI 对其解码器技术道路的坚持;3)模型闭源 逐渐成为头部玩家的发展趋势,这一趋势同样起源于 GPT-3 模型,而 Google 等公司也开 始跟进;4)编解码器路线仍然在持续发展,但是在模型数量上少于解码器路线,或归因于 其复杂的结构,导致其在工程实现上没有明显的优势。大模型或将向更大参数的方向不断演化。我们看到从 GPT-1 到 GPT-4 模型、从 PaLM 到 Gemini 模型,每一代模型的能力在不断强化,在各项测试中取得的成绩也越来越好。而模 型背后的能力来源,我们认为参数和数据集是最重要的两个变量。从十亿规模,到百亿、 千亿、万亿,模型参数量的增加类似人类神经突触数量的增加,带来模型感知能力、推理 能力、记忆能力的不断提升。而数据集的增加,则类似人类学习知识的过程,不断强化模 型对现实世界的理解能力。因此,我们认为下一代模型或仍将延续更大体量参数的路线, 演化出更加智能的多模态能力。拆解来看,大模型的算力需求场景主要包括预训练、Finetune 及日常运营。从 ChatGPT 实际应用情况来看,从训练+推理的框架出发,我们可以将大模型的算力需求按场景进一步 拆分为预训练、Finetune 及日常运营三个部分:1)预训练:主要通过大量无标注的纯文本 数据,训练模型基础语言能力,得到类似 GPT-1/2/3 这样的基础大模型;2)Finetune:在 完成预训练的大模型基础上,进行监督学习、强化学习、迁移学习等二次或多次训练,实 现对模型参数量的优化调整;3)日常运营:基于用户输入信息,加载模型参数进行推理计 算,并实现最终结果的反馈输出。
")
标签: 云计算行业报告
相关文章
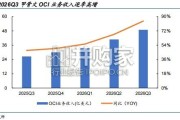
海内外头部算力租赁厂商 ROI 逐步兑现。1)头部算租厂商营收与订单双爆发:海内外算力租赁厂商 ROI 逐步兑 现,甲骨文 FY26Q3 的 OCI...
2026-05-07 29 云计算行业报告

模型跃迁叠加 Agent 出圈引爆推理需求,云厂涨价印证算力斜率依旧。今年以来,我们持 续强调国内算力需求斜率陡峭,核心逻辑在于两大产业趋势共振:1)...
2026-05-02 48 云计算行业报告

2025-2030年,中国数据中心市场新增IT负载预计从5.9GW增至15.1GW,CAGR约+21%,市场规模从2231亿增至6454亿,CAGR约...
2026-04-28 37 云计算行业报告

本报告的核心研究对象是量子计算产业。量子计算机是一种基于量子力学原理构建的计算设备, 是以量子比特(qubit)为基本单元,利用干涉、叠加、纠缠等量子...
2026-04-17 64 云计算行业报告

量子亮相春晚,“量子的未来就在我们手中”。2026 年央视春晚合肥分会场,潘建伟院士手捧“墨子号”模型,掷 地有声地说:“量子的未来就在我们手中”,在...
2026-04-12 49 云计算行业报告

生成式 AI 加速落地、算力需求持续抬升的背景下,全球云厂商资本开支进 入新一轮扩张周期。全球云厂商(CSP)AI 资本开支激进扩张,对承载高功 耗设...
2026-04-06 48 云计算行业报告
最新留言