China’s financing and investment spread across 61 BRI countries in 2023 (up...
2024-02-27 30 英文报告下载
The concept of large lends itself to large language models as a result of being trained on millions of parameters and the use of Natural Language Processing to communicate with the model introduces the language aspect to LLMs.True to its name, Large Language Models are a type of machine learning model that are trained on large parameters of inputs while using natural language to process queries. LLMs are based on transformer architecture and use deep neural networks to generate outputs. Transformer neural networks use the self-attention mechanism to capture relationships between different elements in a data sequence, irrespective of the order of the elements in the sequence.The computational power of transformer models to process data sequencing in parallel on massive data sets is the biggest driving force behind large language models. Breaking down how LLMs work.
The fifirst step in training a large language model is building a large training data set. The data typically is derived from multiple sources across websites, books and other public datasets.The model is then trained using supervised learning, where it is trained to predict output words in a sequence. A LLM learns which words are most commonly used together, the order they appear in and how they relate to each other. These relationships are taught by training the neural network on large datasets. The more data the model is trained on, the better the outputs.The process of training LLMs involves fifirst converting the natural language text data into a numerical representation that can be input into the model. This process of converting the input sequence to a vector representation is called word embedding.The self-attention mechanism of the transformer model then captures the relationship between the input sequence.
")
标签: 英文报告下载
相关文章
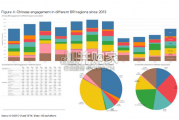
China’s financing and investment spread across 61 BRI countries in 2023 (up...
2024-02-27 30 英文报告下载

Though the risk of AI leading to catastrophe or human extinction had...
2024-02-26 50 英文报告下载
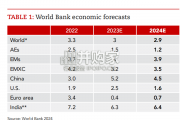
Focusing on the prospects for 2024, global growth is likely to come i...
2024-02-21 95 英文报告下载

Economic activity declined slightly on average, employment was roughly flat...
2024-02-07 66 英文报告下载
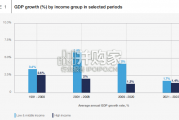
Economic growth can be defned as an increase in the quantity or quali...
2024-02-06 82 英文报告下载
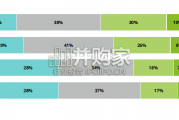
In this initial quarterly survey, 41% of leaders reported their organizatio...
2024-02-05 66 英文报告下载
最新留言